Classificando decisões judiciais com inteligência artificial: segunda parte
Este post faz parte de uma série. Antes de ler, veja o post anterior.
Convencidos da utilidade de um classificador de decisões judiciais quanto ao seu desfecho, passamos a organizar os dados. O primeiro passo foi baixar os acórdãos do STF e elaborar um modelo relacional para estruturar as informações. Basicamente era necessário construir um acervo e os campos nos quais cada acórdão seria fragmentado.
Nesse propósito, foi elaborado um programa de computador capaz de fazer o download e guardar os dados separados por acórdão, classe, número e, especialmente, com identificação da respectiva certidão de julgamento. Como parece intuitivo, essa é uma fase que demanda um enorme investimento em termos de tecnologia, aliado a atenção da equipe de juristas para separar as partes do acórdão a serem consultadas para a posterior classificação das decisões.
Separamos o essencial de forma bastante detalhada e guardamos algumas informações em estado bruto para posterior revisão. Dividimos a equipe em responsáveis por ler as certidões de julgamento de cada classe processual, iniciando pelas seguintes: mandado de segurança, reclamação, habeas corpus e recurso extraordinário. Resolvemos não trabalhar com outros processos, pois eram em número muito pequeno.
Enquanto as primeiras classes tinham poucos milhares de acórdãos cada uma, os recursos extraordinários foram avaliados em volume muito maior. Aliás, seu maior volume sempre foi um obstáculo a pesquisas empíricas de controle difuso de constitucionalidade, pois é preciso mais organização para trabalhar decisões na casa de dezenas de milhares de linhas. Realmente não é algo que um pesquisador apenas possa fazer.
Organizamos esses dados em uma plataforma de anotação, de tal modo que, em conjunto, a equipe de juristas tivesse condições de propor um modelo inicial de classificação de resultados dos acórdãos. Depois de muita discussão sobre as opções de construir um classificador mais complexo ou mais simples, surgiu o seguinte modelo:
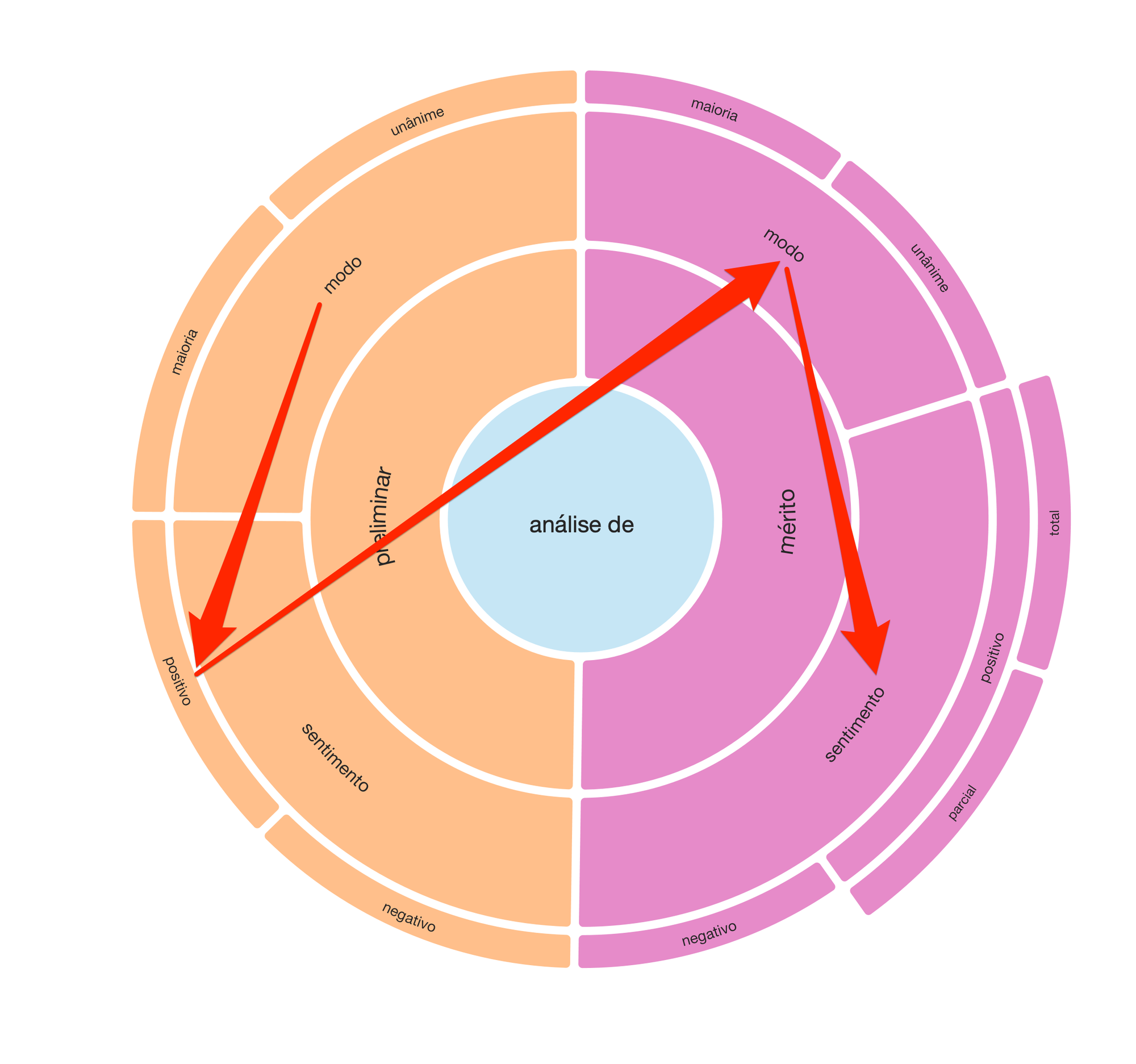
Decidimos, assim, realizar um juízo preliminar (por maioria ou unanimidade), o qual, se positivo, levaria à avaliação do mérito. Do mesmo modo, o juízo de mérito foi bipartido em seus modos (maioria ou unanimidade) e respectivos desfechos: positivo e negativo. Por fim, especificamente para o juízo de mérito positivo, dividimos também a avaliação pela abrangência do provimento: total ou parcial.
A partir dessa sequência de juízos, ilustrada no radial, teríamos condição de ampliar a amostra para a casa das dezenas de milhares de acórdãos de forma consistente.
O que faltava apenas era uma plataforma de anotação que fosse capaz de abrigar esse trabalho, permitindo o acesso simultâneo dos pesquisadores ao acervo. Transferimos então o acervo para uma infraestrutura em nuvem dotada dessa capacidade e iniciamos a classificação. Um exemplo simplificado de como os dados estão estruturados, tomando como exemplo os mandados de segurança, é o seguinte:
Embora algumas partes da tabela tenham sido omitidas (o que preserva a originalidade da pesquisa até sua publicaçãoo), já é possível notar a estrutura que montamos para anotação do modo (maioria ou unânime). A título de exemplo, no caso dos recursos extraordinários, classificamos 3.972 acórdãos como unânimes, tendo as seguintes variações: unanimamente, unanimidade, unânime, acordo de votos e decisão uniforme.
Isso significa que, nesse ponto, nossa base de dados passou a contar com quase quatro mil vínculos devidamente etiquetados. São processos reais, dos quais conhecemos diversos atributos. A mesma filosofia vale para o vocabulário presente no acervo para classificar o desfecho (positivo ou negativo) do julgado. A diferença é que existem não apenas cinco, mas centenas de variações de palavras utilizadas para traduzir o desfecho de um acórdão.
Como sabemos muito sobre cada um desses processos, torna-se possível treinar uma máquina para que, reconhecendo um padrão, sugira uma etiqueta contemplando o modo (por exemplo, unânime) e o desfecho (por exemplo, desfavorável) diante um novo acórdão que venha a ser prolatado. Assim, ensinamos a máquina classificar rapidamente milhares de novas decisões, a partir da curadoria realizada pelos nossos pesquisadores.
O aprendizado de máquina em si também não é uma tarefa trivial e será objeto de um novo post. Tratamos até agora apenas da prepração dos dados, que é uma etapa essencial e frequentemente negligenciada. Sem dados devidamente organizados, não é possível desenvolver soluções de inteligência artificial.