DireitoTec
IA na Folha de São Paulo: matéria ou publi?
Comentário sobre as matérias da Folha de São Paulo sobre aplicações de inteligência artificial no mundo do Direito.
A Folha de São Paulo publicou recentemente uma série de matérias sobre inteligência artificial. Apesar do anúncio incomum, o artigo não foi promovido como um publieditorial. Este é o cabeçalho da matéria de 20/02/20:
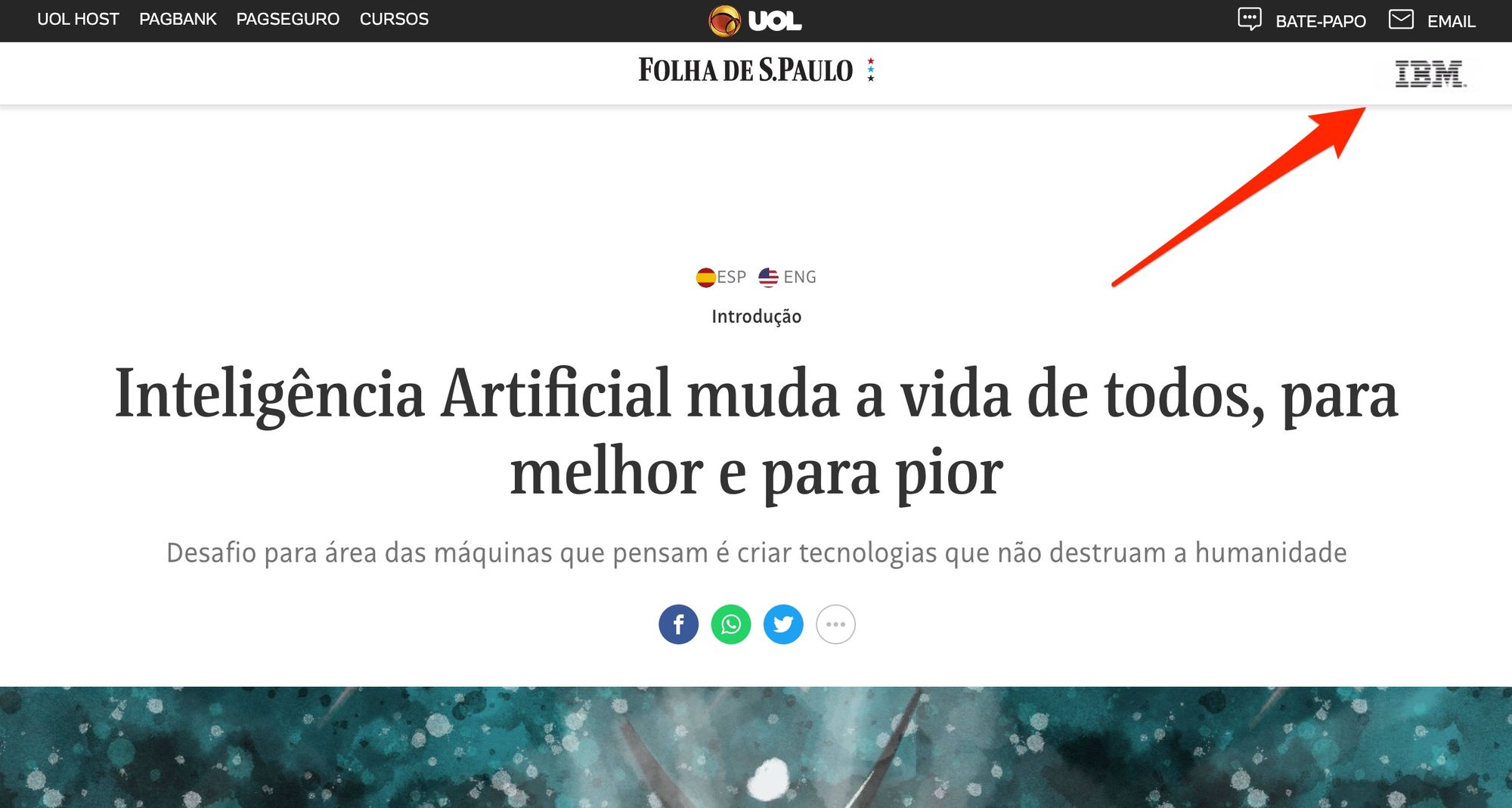
E este é seu rodapé:
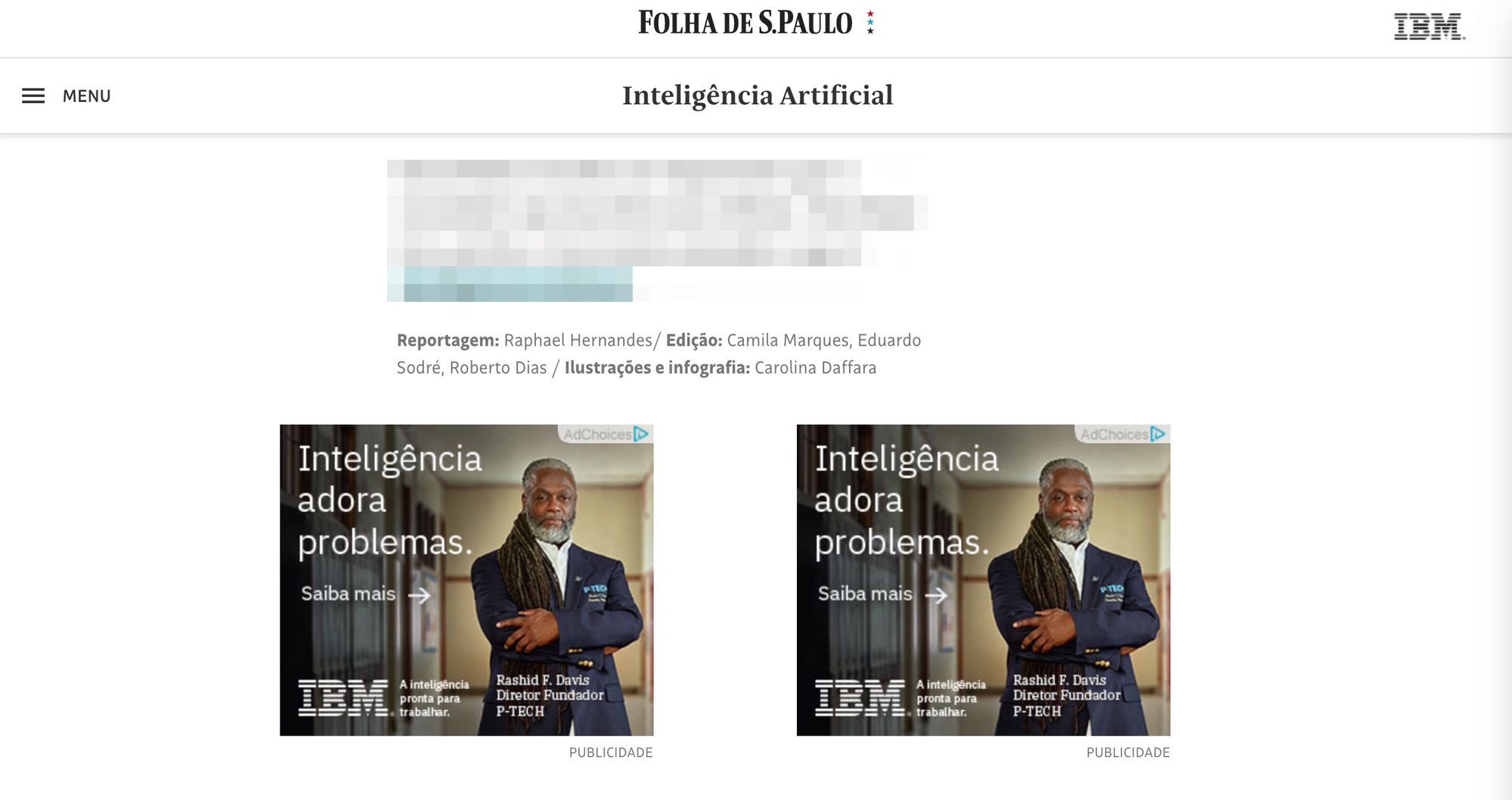
Ou seja, pode até não ser um publieditorial, mas é uma coluna patrocinada com certeza. Isso demonstra que a Folha está engajada em uma atividade educativa (louvável), o que não nos desonera de considerar os patrocinadores quando encontramos alguma notícia que nos seja especialmente interessante.
Muito bem. Nesse contexto, a Folha publicou também em 10/03/20: "Inteligência artificial atua como juiz, muda estratégia de advogado e promove estagiário".

Como não sei se meu comentário seria autorizado no sistema da Folha, deixou aqui meu roteiro de leitura do artigo. Espero que, com essas advertências, a matéria se torne mais informativa sobre o uso da Inteligência Artificial (IA) no Direito:
- Folha: "Segundo a versão mais recente do "Justiça em Números" (...), 108,3 milhões de causas tiveram início em versão digital de 2008 a 2018". Eu: Isso não é muito relevante para IA, uma vez que o que foi transferido para a plataforma digital foi a tramitação. Os autos continuam a ser PDF normais, os quais não fornecem facilmente o tipo de dados que sistemas inteligentes consomem.
- Folha: "Ilustração de Diana, nome dado ao programa de inteligência artifical do escritório Lee, Brock e Camargo Advogados". Eu: Sério?
Folha: "Macêdo utiliza no dia a dia o sistema, batizado de Elis (no Judiciário de Pernambuco)". Eu: Tudo bem que batizar coisas seja divertido. Mas será que precisamos de mais um robô em 2020?
Folha: "No texto da própria decisão está dizendo que foi Elis quem fez, para permitir transparência no processo, para que se saiba o que está sendo usado." Eu: Você coloca na decisão que foi feito em Word ou máquina de escrever?
Folha: "Segundo Juliana Neiva, secretária de Tecnologia da Informação e Comunicação do tribunal, o desenvolvimento da IA teve custo zero para a corte, pois foi desenvolvido por servidores do próprio órgão." Eu: Os servidores são custo zero?
Folha: "O STJ quer ir mais longe no uso da tecnologia e relata que já está em andamento o projeto Sócrates 2, no qual a ideia é avançar para que a IA em breve forneça de forma organizada aos juízes todos os elementos necessários para o julgamento das causas, como a descrição das teses das partes e as principais decisões já tomadas pelo tribunal em relação ao assunto do processo." Eu: Será que IA é a melhor (ou única) forma de fazer isso?
Folha: "Para lidar com esse problema, o escritório Lee, Brock e Camargo Advogados (LBCA) desenvolveu um aplicativo ligado a um sistema de IA. O mecanismo possibilita levantar, logo após conhecer quem são os depoentes da parte adversária, tudo o que essas testemunhas já disseram em outros processos, afirma Solano de Camargo, sócio fundador do LBCA." Eu: Alguém acha que precisa de IA para isso? Será que esse é realmente um problema central para um escritório de contencioso de massa? O importante não é saber o que o a testemunha falará sobre os fatos daquele determinado processo?
Folha: "O sistema de IA do escritório foi batizado de Diana e já consumiu investimentos de R$ 3 milhões nos últimos anos, diz Camargo. O custo inclui a implantação de um laboratório de tecnologia interno que conta com 41 integrantes." Eu: Com 41 integrantes, você nem precisa de inteligência artificial. Todo o sentido da tecnologia é dar mais produtividade para que você possa ter equipes pequenas.
Folha: "Exemplos de uso: O escritório Lee, Brock e Camargo Advogados (LBCA), de São Paulo, desenvolveu um sistema de IA e um aplicativo conectado a ele. Os advogados da banca podem abrir o aplicativo no decorrer de audiências e usar as análises do software para identificar, por exemplo, contradições de uma testemunha enquanto ela fala ao juiz" Eu: Preciso escrever um post sobre isso.
A Folha de São Paulo é um jornal muito importante e, no meu modo de ver, deveria ser mais seletiva em suas publicações. É natural que um jornal tenha anunciantes. Não é normal, contudo, desinformar dessa maneira. Seria bem legal que a Folha desse sequência na matéria de uma maneira menos capturada. Ou então deixasse mais claro quem é o anunciante, sob pena de se tornar apenas mais uma página na internet.
Demo do Estatuto do Desarmamento: segunda parte
Demonstração das funcionalidades de busca global e criação de relacionamentos entre dispositivos normativos.
Este post faz parte de uma série de pesquisas para possíveis melhorias no acompanhamento de proposições legislativas. Embora nossa meta seja submeter o projeto ao LABHacker (Laboratório de Inovação Cidadã da Câmara dos Deputados), trata-se atualmente de uma iniciativa independente. As informações foram coletadas do site Dados Abertos e do Portal da Câmara, sendo utilizadas aqui em conformidade com os seus termos de uso.
Dando sequência à demonstração de novas formas de exibição do Estatuto do Desarmamento, preparamos uma segunda parte do ensaio. Aqui nosso objetivo inicial é explorar a busca simultânea em múltiplos documentos, o que chamaremos de busca global.
Nesse propósito utilizaremos um aplicativo chamado Dynalist, mas poderíamos utilizar outros, por exemplo: Workflowy, Checkvist ou Moo.do. Essa opção decorre de que ainda não temos essa funcionalidade incorporada na nossa plataforma, ao passo que já se trata de um comportamento padrão dos "outliners" de uso gratuito.
Nosso diferencial é que somos capazes de gerar, com apenas um clique, os arquivos com as normas devidamente estruturadas. Assim, os arquivos foram gerados no nosso ambiente e estão sendo apenas exibidos em programa de uso comercial. Se nossa comunidade confirmar interesse nessa funcionalidade, ela será desenvolvida para a nossa plataforma, mas hoje ela ainda não está disponível.
Bem, registrada a ressalva, vamos à demonstração.
Enquanto a busca em um acervo geralmente retorna uma lista de documentos, o comportamento demonstrado neste post consiste em trazer os documentos relevantes já abertos e filtrados. Tal filtro destaca a exibição dos fragmentos em que a busca retornar um resultado positivo. Além disso, para dar um pouco de contexto, são exibidos também os fragmentos hiearquicamente superiores, os quais funcionam como uma espécie de "migalhas" para que se saiba o caminho até o fragmento de destino.
Na primeira parte da demonstração, esse comportamento e suas vantagens já chegaram a ser comentados. Mas somente agora demonstramos como é possível fazer isso com diversos documentos simultaneamente. É mais fácil ver em funcionamento do que explicar:

Na barra lateral esquerda está o acervo relevante. No caso, foram selecionados um PL, uma lei e o Código Penal. Ao buscar pela palavra "disparo", o sistema revela que a palavra tanto está presente na lei quanto no PL. A diferença está em que, na lei atual, ocorre a vedação ao disparo pelo caçador para subsistência que der outro uso a sua arma. Já no PL, a palavra ocorre para registrar que o colecionador não pode efetuar disparos.
Por seu turno, é possível notar que, tanto na lei quanto no PL, o disparo de arma de fogo continua previsto como um crime. No nosso modo de ver, essa é a forma ideal de realizar consultas rápidas em múltiplos documentos, pois a própria hierarquia normativa já auxilia bastante na comparação. Afinal, logo de início, você percebe se a comparação está no contexto dos "crimes e das penas" ou do "porte" ou da "aquisição e do registro".
Essa consciência situacional imediata economiza muita carga mental do intérprete.
Mais alguns exemplos ajudam a ilustrar a funcionalidade. Vejamos como o sistema se comporta com a busca por "omissão" e depois por "arma de fogo":
Outros sistemas de informação exigiriam muito mais interações para chegar ao mesmo grau de evidência. Só o fato de não existir paginação (idas e vindas), já auxilia bastante a manipulação do conteúdo. Nesse sentido, a experiência é similar ao que se espera do Google: a solução imediata da questão. De outro lado, não somos avessos a tentar um novo argumento de busca, pois essa é a prática que já temos em outras ferramentas. Queremos que a resposta esteja sempre na primeira página. Pelo menos é assim que eu, pessoalmente, faço minhas buscas.
Assim provamos que é possível buscar e ler diversos documentos na mesma tela, sem mudar de página.
A alternativa até agora, para uma investigação como essa, seria montar uma planilha Excel, que não tem busca. As pessoas estavam acostumadas a copiar e colar textos para programas feitos para fazer operações matemáticas, o que não é um uso racional. Chegamos a ver, mais de uma vez, textos normativos enormes colados em uma planilha, de modo que o leitor tivesse alguma noção sobre o paralelo dos fragmentos em diversas normas.
E isso nos leva ao segundo objetivo, consistente não apenas em nos orientarmos pela estrutura normativa embutida na lei, mas também a poder criar relacionamentos entre fragmentos de diferentes documentos. Em outras palavras, como criar relacionamentos sem ficarmos presos na metáfora da linha de Excel?
Nossa proposta é viabilizar que um documento possa ser consultado dentro do outro, abrindo-se uma janela para criação do vínculo manualmente. Dessa maneira, a navegação se torna muito mais fluida:
Precisamos reconhecer, contudo, que a experiência ainda seja um tanto truncada, pois realmente é algo muito complexo: navegar dentro de um texto estruturado, criando relacionamentos com pontos de outro texto estruturado. Não é uma tarefa fácil, especialmente no caso de estarmos criando referências "inline". Talvez o servidor responsável por criar esses vínculos deva ser um especialista.
Já para o leitor, contudo, a experiência parece agradável, pois o que ele nota é apenas um link dentro do texto, que o remete para um determinado ponto de outro texto, com o qual guarda relação. Por exemplo, o Art. 46 do PL é relacionado aos Arts. 12 e 14 da lei antiga:

Em outras palavras, criar um texto estruturado dessa forma sempre foi difícil. Agora passou a ser possível, apesar da dificuldade. A vantagem é que, uma vez criado, o leitor terá muita facilidade em ver relações entre pontos de documentos normativos que antes ficavam ocultos.
Isso pode ser útil, por exemplo, na organização e na votação de emendas, pois sem dúvida trata-se de um momento em que dois textos precisam ser confrontados com clareza. De outro lado, pode ser útil para quem pesquisa e compara os textos normativos ou, quem sabe, para quem minuta uma proposta de texto.
De todo modo, para fim de prova de conceito, parece estar demonstrado que é possível consultar diversos textos (ou diversas versões de um mesmo texto) com uma busca bastante intuitiva e rápida. Atualmente, até onde vai nosso conhecimento, não existe uma ferramenta que facilite a comparação de textos dessa natureza.
Texto apresentado no VIII Congresso Internacional de Direito do Trabalho, realizado em outubro de 2018.
Reformulando a questão
Honestamente, não sei responder à pergunta que me foi proposta: “Quais as habilidades o trabalhador do futuro terá (ou precisará ter)?”
De todo modo, é uma questão que me intriga e, por isso, gostaria de pelo menos responder a uma pergunta conexa, mas menos abrangente. Então tomarei a liberdade de reformular o problema, enfrentando o assunto dentro daquilo que me parece pertinente e possível de ser respondido: Quais são as habilidades que o jurista do futuro terá (ou precisará ter)?
Isso se confunde um pouco com uma exposição sobre o que tenho feito academicamente e com aquilo que está acontecendo no mundo como um todo, por assim dizer, da indústria jurídica. Sei que esse nome não é o ideal, mas ao menos parece fiel ao fato de que o Direito existe como um campo da cultura, ao mesmo tempo em que existe como um ramo de atividades profissionais. Afinal, é com a prática do Direito que o jurista ganha a vida.
No meu modo de ver, como docentes, empenhamos muita energia em introduzir os bacharelandos no mundo do conhecimento jurídico, mas praticamente ignoramos que o estudante de graduação precisa também pensar como exercerá sua atividade profissional.
Atentos a esse fato, professores de Harvard organizaram o Center on the Legal Profession, cuja missão é assim declarada: prover uma compreensão mais rica das rápidas mudanças que estão ocorrendo globalmente nas profissões jurídicas. Apesar de tal centro oferecer uma reflexão bastante rica sobre a advocacia globalizada, esse traço é também limitante, tendo em vista que se propõe a avaliar justamente a advocacia que serve às empresas globais.
Diante disso, o futuro da advocacia local - como um mercado totalmente diferente do globalizado - demanda reflexão própria. E, do mesmo modo, todas as profissões jurídicas que não se enquadram dentro da advocacia precisam ser observadas de outros pontos de vista.
A história brasileira desde as primeiras faculdades
Com a invasão de Portugal pelos franceses, em 1808, sucedeu a transferência da corte portuguesa para o Brasil. Em decorrência disso, houve uma série de evoluções locais, por exemplo, a abertura dos portos, a construção de fábricas e a fundação do Banco do Brasil.
Em 1822 o Brasil veio a se tornar independente, o que estimulou a criação de dois cursos de Direito em 1827, de modo que a elite residente no país tivesse condição de estudar sem voltar para a Europa. Nesse cenário, é possível imaginar que as profissões jurídicas tenham sido bastante diferentes do que temos hoje, organizando-se, basicamente, em torno da missão de estruturar um jovem país independente. Assim, as primeiras faculdades de Direito foram responsáveis por prover a elite que ocuparia os postos políticos e administrativos do Brasil.
Somente por volta de 1930, com o crescente processo de industrialização, teve início a organização do direito empresarial. Até então, os assuntos relativos à propriedade, família e sucessões eram os mais importantes para a prática jurídica. Com a Segunda Guerra Mundial, o crescimento da indústria foi ainda mais acelerado, demandando a organização jurídica dos assuntos bancários, contratuais, exportações, entre outros.
Outro aspecto relevante é que, também durante a Era Vargas, ocorreu um crescimento do papel do Estado, criando demanda para a evolução do direito público, especialmente do direito administrativo. No entanto, mesmo diante da demanda por uma atuação técnica mais especializada dos profissionais do Direito, isso não ofuscou a presença da formação jurídica como uma das características essenciais dos políticos brasileiros.
Somente após 1964, com a instauração do Regime Militar, o cenário viria a mudar. Em que pese as liberdades civis e os direito humanos tenham sido negligenciados no período, alguns ramos jurídicos mais técnicos passaram por evolução considerável. São marcos do período a criação do Banco Central, do Conselho Monetário Nacional, além de desenvolvimentos nos campos do Direito tributário e societário.
Ao longo das décadas de 70 e 80, aumentou o número de advogados brasileiros que complementaram sua formação nos Estados Unidos. E, nos anos 90, com o avanço da globalização, esse tipo de serviço passou a ser ainda mais demandado. Tal demanda ocorreu em duas frentes, tanto pela ampliação da atuação das empresas brasileiras no exterior, quanto pela chegada de investimentos estrangeiros especialmente em decorrência das privatizações e novas concessões em andamento.
A partir desse momento, o mercado da advocacia brasileira passou a contar com uma força de trabalho realmente organizada e orientada a atender à demanda de uma economia globalizada.
Mas essa parte da advocacia brasileira sempre foi minoritária, tendo em vista que, ao mesmo tempo, cresceu enormemente a oferta de vagas nos cursos de Direito. E a maioria desses profissionais viriam a prover serviços em uma dinâmica interna que nada se relaciona com a globalização e que, muitas vezes, é uma resistência ao avanço de sua cultura.
Especialmente na última década, quanto alguns escritórios estrangeiros chegaram ao Brasil (por exemplo, Mayer & Brown e DLA Piper) enfrentaram forte resistência. O maior opositor da investida estrangeira é Centro de Estudos das Sociedades de Advogados (Cesa), da qual fazem partes grandes escritórios brasileiros. A resposta da OAB à demanda do Cesa, embora não tenha encerrado as parcerias operacionais entre os mencionados escritórios estrangeiros e seus respectivos parceiros brasileiros, levou ao fim da dupla Lefosse e Linklaters, escritório britânico com atividades no Brasil desde 2001.
Existe, portanto, uma tensão que não se dissipou totalmente entre os escritórios estrangeiros e a advocacia local. Cada vertente representa uma cultura e demanda profissionais com diversos perfis. Esse é um dos motivos pelos quais não podemos pensar no futuro das profissões jurídicas no Brasil somente a partir de constatações e reflexões promovidas por centros de estudo estrangeiros.
As competências para quem já está no mercado
Um escritório grande, por exemplo, com mais de cem advogados, é marcado por duas características: a primeira é que sua vantagem competitiva consistente em manter o seu cliente abrigado em todas as suas necessidades; a segunda, bastante relacionada à primeira, consiste em que cada advogado atua segundo sua especialização. Existe, portanto, um grau relevante de impessoalidade no trato.
Em razão dessas características, um advogado de um escritório grande (big law) deverá responder à cultura do escritório e seu progresso é relativamente previsível dentro da organização, baseado na pauta desses valores. Atualmente os escritórios grandes tentam passar uma imagem de inovação, não apenas de tradição. Isso se deve ao fato de que a forma de organização do big law passa por enormes ameaças no mundo inteiro.
Embora seja compreensível que os grandes escritórios não demonstrem sua vulnerabilidade publicamente, é fácil verificar sua existência a partir de uma linha de pesquisa do Center on the Legal Profession de Harvad, chamada “The reemergence of the Big Four in Law”. Isso significa que as grandes firmas de contabilidade, que são muito maiores e mais eficientes que qualquer escritório de advocacia, estão avançando agressivamente sobre o mercado.
Em face disso, no meu modo de ver, precisam estar entre as competências de um futuro sócio de um grande escritório de advocacia: conhecimento sobre o atual modelo de negócio da advocacia; conhecimento sobre os modelos de negócio alternativos; e conhecimento sobre as forma de integração dos serviços jurídicos com serviços de apoio.
Penso que nenhuma competência tecnológica seja relevante para figurar como advogado desse mercado, tendo em vista que a grande ameaça deriva de uma questão negocial.
O modelo de negócio dos escritórios internacionais está ameaçado e, na minha opinião, os sócios que souberem como promover a defesa de suas organizações serão recompensados.
Em contraste, para o mercado nacional e para os escritórios menores, considero que os juristas do futuro precisam investir em outro rol de competências. Como seu mercado não está propriamente ameaçado pelas grandes firmas de contabilidade, não existe contra ele um risco de máxima magnitude.
No entanto, esse tipo de advocacia precisará lidar com adversidades: o potencial aumento de tecnólogos do Direito, o que tende a reduzir as margens em serviços de menor valor agregado; e o aumento da concorrência local, tendo em vista que plataformas de processo eletrônico permitirão uma concorrência nacional em qualquer mercado contencioso.
Como consequência, os escritórios de advocacia menores tenderão a atuar em nichos cada vez mais determinados, mas sem limitações territoriais. Então, no meu modo de ver, o futuro pertence ao especialista. Suponho que o generalista venha a perder espaço também em razão do amadurecimento das plataformas que deverão servir informações sobre a qualidade e a reputação de cada escritório, de maneira que o especialista possa ser mais facilmente encontrado.
Tudo leva a crer que o custo de encontrar um bom advogado a um preço justo será diminuído por meio de plataformas virtuais que venham a promover o equilíbrio entre a oferta e a demanda por tais serviços.
Suponho que pequenos escritórios venham a ganhar com isso, pois serão mais eficientes em prover diretamente o trabalho, sem fazer frente aos grandes custos de manutenção de um escritório luxuoso ou voltado a manter relações comerciais a partir das aparências.
Por fim, quanto ao setor público, existe uma dinâmica ainda mais diferente. Suponho que o serviço público venha a passar por tempos de restrição orçamentária, o que vai demandar do gestor maior produtividade. Do ponto de vista da chefia, mais produtividade demandará um aprendizado sobre gestão de equipe de uma maneira ágil e orientada a resultados. Afinal, o gestor público precisará fazer mais com menos. Essa demanda parece ter se intensificado nos últimos meses.
Ainda quanto ao ambiente público, do ponto de vista do servidor público subordinado, competências complementares às da chefia serão valorizadas, por exemplo, a capacidade de montar um sistema computacional de baixo custo a partir de serviços prestado via nuvem. Isso não demandaria a capacidade de escrever em linguagem de computador, mas certamente demandaria uma mente mais analítica do que a tradicionalmente orientada por habilidades verbais e de comunicação.
Imagino assim que a era da valorização da eloquência e da capacidade de expressão tenha chegado a um ponto em que tais virtudes passarão a concorrer com outras competências desejáveis. Sob esse enfoque, as qualidades tradicionais de um jurista passarão a ter menos valor. Sobretudo o conhecimento decorado e irrefletido passará a ter menos valor do que já tem hoje, pois os sistemas de recuperação de informação tendem a ser aprimorados.
Enquanto a iniciativa privada tem, naturalmente, mais agilidade para se adaptar e modificar o perfil de sua força de trabalho, o concurso público tem um formato rígido e legalmente imposto. Assim, o poder público tende a manter um formato antiquado de seleção de servidores, sendo desejável que invista em soluções para aprimorar as competências da sua força de trabalho já em atividade.
As competências para quem ainda vai entrar no mercado
O Ministério da Educação publicou recentemente, por meio da Resolução 05/18, novas Diretrizes Curriculares Nacionais para o curso de Direito. Entre as novidades estão a preocupação com o fortalecimento das formas consensuais de composição de conflitos. Além disso, o MEC entende desejável que os egressos do bacharelado em Direito sejam capazes de trabalhar em um ambiente de diversidade e pluralismo cultural, desenvolvendo capacidade de trabalho em grupo e em contexto interdisciplinar.
Do ponto de vista tecnológico, o MEC estabeleceu que o curso de Direito deverá possibilitar a formação de competências para que o bacharel compreenda o impacto das novas tecnologias na área jurídica. Penso que foi acertado ao MEC não enumerar quais seriam essas tecnologias, pois realmente o escopo das Diretrizes Curriculares é orientar genericamente a elaboração do Projeto Pedagógico de Curso.
No que concerne, portanto, aos mais jovens, cuja formação ocorrerá sob as Diretrizes Curriculares atuais, o impacto da inovação será ainda maior sobre suas carreiras. O reconhecimento, por parte do MEC, de que a tecnologia desempenhará um papel protagonista nas profissões jurídicas surge, no meu modo de ver, como um diagnóstico conservador.
Com uma postura mais arrojada, Richard Susskind (Susskind, 2017) propõe uma série de novas atividades, as quais seriam desempenhadas pelos novos advogados, num futuro em que devem ser dotados de menos prestígio profissional. São elas: consultoria jurídica desempenhada por advogados em casos extremamente especializados, nos quais o profissional tenha uma forte relação de confiança com o cliente; bem como atividades de apoio tecnológico a essa consultoria.
Para além disso, Susskind sustenta que serão criadas novas profissões, resumidas aqui em tradução livre.
Os Engenheiros de Conhecimento Jurídico seriam os advogados responsáveis por analisar e parametrizar a linguagem e os conceitos jurídicos para que possam ser incorporados a programas de computador. Já os Engenheiros de Tecnologia Jurídica seriam uma profissão que até hoje foi desempenhada por pessoas de uma dessas duas áreas: Direito ou Tecnologia. Sua missão seria viabilizar o consumo de serviços jurídicos independentemente da mediação de um advogado.
Passariam a existir também Advogados Híbridos, igualmente versados em duas áreas do conhecimento, cuja missão seria, por exemplo, criar uma estratégia de negociação ou atuar como psicólogos. O autor reconhece que, de algum modo, essa prática já existe, mas o que propõe é que o advogado não tenha apenas uma noção da área do conhecimento de forma secundária, exibindo sólida formação em igualdade de condições com seu conhecimento jurídico.
Uma variação desses profissionais seriam os Cientistas de Dados Jurídicos. Eles precisariam ter sólida formação em matemática, estatística e programação. Ou seja, tal descrição não é a de um advogado que opera sistemas de computador já prontos, pois, para o desempenho dessa atividade, é necessário capturar, analisar e manipular grandes quantidades de dados com bastante desenvoltura técnica.
Assim como hoje a indústria de eletrônicos e a farmacêutica contam com laboratórios de inovação, Susskind aponta que devem passar a existir os Profissionais de Pesquisa e Desenvolvimento em Direito. Eles seriam responsáveis concepção de serviços e soluções a partir de técnicas experimentais, atuando com muito mais liberdade do que os profissionais alocados na parte operacional dos escritórios e das empresas ligadas à área jurídica.
Susskind menciona também que outra profissão seria a dos Analistas de Projeto Jurídico. Tais analistas não se confundiriam com meros operadores de sistemas já prontos, consistindo sua prática na decomposição de tarefas a serem distribuídas a diversos fornecedores. Sua função seria desagregar as tarefas de um projeto, terceirizando a execução, cuja gestão estaria a cargo de um outro tipo de profissional, o Gestor de Projeto Jurídico.
Assim como as gigantes da contabilidade criaram um ramo de prestação de serviços de consultoria a partir dos seus negócios iniciais de auditoria, Susskind acredita que os escritórios de advocacia devem evoluir em uma direção similar, criando as condições para o estabelecimento dos Consultores de Gestão Jurídica.
Embora, por exemplo, as atividades de gestão e instrução de equipes já existam dentro dos departamentos jurídicos, geralmente são prestadas de forma pouco especializada. Outros serviços que seriam abarcados por essa atuação profissionais incluem: análise da cadeia de valor, estruturação organizacional, recrutamento de profissionais, gestão da informação, etc.
Há ainda uma parte muito específica desse tipo de serviço, concernente à identificação, quantificação, monitoramento e prevenção de riscos. Esse seria o campo de atuação dos Analistas de Risco Jurídico. Seu papel seria auxiliar os Diretores Jurídicos, em uma frente na qual existe um enorme déficit de profissionais.
Por fim, a parte de serviços prestados por plataformas online, o autor aponta que devem passar a existir os Mediadores Online.
Conclusão
Em um cenário de tanta incerteza e carência de análise sobre as particularidades do mercado das profissões jurídicas no Brasil, é realmente muito difícil saber quais são as competências do jurista do futuro.
Diante disso, independentemente do momento da carreira do interessado, o mais prudente parece ser se envolver profundamente com o mercado de trabalho no estado em que se encontra. A partir da compreensão do seu estado atual e das suas fragilidades, cada um poderá se organizar para aproveitar as oportunidades que se apresentarão.
Sem se envolver com o mercado real, as oportunidades não poderão ser nem percebidas como oportunidades reais, pois tudo estaria no campo da conjectura. Então estar atento às mudanças é a melhor recomendação que eu poderia dar, pelo menos a mais honesta.
É certo que, para aqueles mais focados em tecnologia, pode ser conveniente buscar se instruir formalmente em algum campo das ciências exatas. Em contraste, para as pessoas com mais aptidão comercial e de relacionamento, convém seguir atentos às modificações atinentes ao modelo de negócio da prestação de serviço jurídico.
No entanto, o maior interessado na resposta deste texto parece ser o estudante que ainda não e encontrou em nenhum desses extremos. O mais provável é que uma boa Faculdade de Direito brasileira esteja orientada a transformar seus egressos em pessoas capazes de desempenhar uma atividade de representação judicial, mediante atendimento pessoal, trabalhando passivamente sob medida para a causa que o cliente venha a lhe apresentar. Ou seja, essa é definição tradicional de advogado.
De outro lado, as Instituições de Ensino parecem investir pouco no desenvolvimento de competências voltadas ao trabalho em equipe, bem como na instrução híbrida de um perfil jurídico e também tecnológico, fortemente orientado a atender demandas do mercado e voltado a funcionar segundo as necessidades do mundo corporativo.
Imagino que o esforço do estudante para suprir tais lacunas em sua formação venha a ser recompensador, caso se confirmem as premissas supostas neste texto. Bem, ao menos essa é a minha reflexão para hoje.
Bibliografia
ABREU, Arthur Leal; FERRARI, Juliana. A formação do profissional jurídico do futuro. Disponível em: https://www.jota.info/carreira/diretrizes-curriculares-profissional-juridico-10052019. Acesso em: 11 maio 2019.
FEFERBAUM, Marina. Entenda o futuro dos curso e das profissões do Direito. Disponível em: http://revistaensinosuperior.com.br/futuro-do-direito. Acesso em: 11 maio 2019.
CUNHA, Luciana Gross et al. The Brazilian Legal Profession in the Age of Globalization. Cambridge: Cambridge University Press, 2018. Disponível em: https://doi.org/10.1017/9781316871959. Acesso em: 11 maio 2019.
HARVARD LAW SCHOOL. Center on the Legal Profession. Website. Disponível em: https://clp.law.harvard.edu. Acesso em: 11 maio 2019.
MAHARG, P. Transforming Legal Education: Learning and Teaching the Law in the Early Twenty-First Century. Aldershot: Ashgate Publishing, 2007.
ROBINSON, N. When Lawyers Don’t Get All the Profits: Non-Lawyer Ownership, Access, and Professionalism. Rochester, NY: Social Science Research Network, 27 ago. 2014. Disponível em: https://papers.ssrn.com/abstract=2487878. Acesso em: 12 maio. 2019.
SUSSKIND, R. E. Tomorrow’s lawyers: an introduction to your future. Oxford: Oxford University Press, 2017.
SUSSKIND, R.; SUSSKIND, D. The Future of the Professions: How Technology Will Transform the Work of Human Experts. Oxford: Oxford University Press, 2015.
WILKINS, D. B.; FERRER, M. J. E. The Integration of Law into Global Business Solutions: The Rise, Transformation, and Potential Future of the Big Four Accountancy Networks in the Global Legal Services Market. Law & Social Inquiry, v. 43, n. 3, p. 981–1026, 2018. Disponível em: https://doi.org/10.1111/lsi.12311. Acesso em: 11 maio 2019.
No último British Legal Technology Forum, realizado em Londres nesta semana, foram discutidos vários assuntos relacionados a inteligência artificial aplicada ao direito. O blog Artificial Lawyer esteve lá e publicou uma reflexão interessante sobre uma nova onda de opiniões sobre inteligência artificial, a qual chamou de “Post-Hype AI Hype”.
Para quem não está familiarizado, hype é algo exagerado e com uma conotação negativa. Está em hype qualquer assunto que esteja dando o que falar, que esteja na moda, mas que ao mesmo tempo não tenha fundamento comprovado. No contexto da tecnologia, algo que esteja em hype traz consigo um grande receio de que o estado atual da tecnologia não seja suficiente para solucionar os problemas que se propõe a enfrentar.
O movimento atual, diagnosticado nesta semana ainda, sustenta que o ciclo de expectativas exacerbadas sobre o potencial da inteligência artificial estaria chegando ao fim. No lugar de discutir um futuro distante, esse movimento tem como objetivo refletir sobre aplicações práticas e imediatas, as quais geralmente demandam tecnologias já sedimentadas. Ou seja, formou-se um novo ciclo no setor contra a inteligência artificial - mas que não deixa de ser igualmente uma espécie de hype.
No fundo, temos agora um novo hype assumindo o lugar do outro. Nenhum deles foi deliberadamente criado, pois foi composto de uma soma de vozes que realmente acreditavam naquilo que prometiam como solução de todos os problemas. Hoje, recauchutado, o hype se organiza para evitar a terminologia até então celebrada, mas isso não é algo que venha sem qualquer dificuldade. Afinal, ainda que de forma imprecisa, inteligência artificial já é um termo incorporado ao vocabulário corrente. De toda forma, isso viabilizou a comunicação até agora.
Debater assuntos conexos falando de aprendizado de máquina, processamento de linguagem natural, classificação automática de decisões, entre outros termos, é algo que demandaria muito mais energia. Trata-se de algo que certamente não é do interesse das empresas que utilizam o jargão apenas como marketing, sem nenhum compromisso em embarcar a tecnologia que anunciam em seus produtos.
Parece que o termo inteligência artificial perdeu o seu frescor. Ao mesmo tempo - e não por acaso - algumas de suas promessas simplesmente não foram concretizadas para o mercado jurídico. Vivemos uma ressaca semelhante àquela que recentemente passou a medicina, pois a inteligência artificial não descobriu a “cura do câncer”. E nós continuamos sem a “cura para os processos”.
De ciclo em ciclo, o hype se revela como o próprio modo de ser de comunidades profissionais com domínio limitado sobre o que deveria ser discutido e compreendido em profundidade. Uma vez instalado, ele não se dissolve facilmente, sendo sucedido por uma nova promessa que também não se realizará. Esse encadeamento de promessas e frustrações é típico dos setores que consomem tecnologia, sem que tenham as ferramentas para sua compreensão total.
Assim, o hype é consequência da nossa própria falta de domínio técnico, da nossa consequente superficialidade nesse campo. São ingredientes adicionais o interesse de pessoas de alimentarem o hype, por exemplo, um conferencista que reafirme seu suposto saber ou empresas que vendam o hype, pois elas funcionam na lógica de uma comunicação imediata e facilitada.
Os elementos finais são as palavras inteligência e artificial, que transmitem um sentido bastante equívoco daquilo que realmente são quando utilizadas em conjunto. Seria melhor que essa tecnologia não tivesse seu conteúdo induzido por vocábulos que achamos que compreendemos, pois fazem parte da nossa linguagem em outros contextos.
Embora um advogado entenda plenamente os desafios jurídicos do seu trabalho diário, dificilmente compreenderia tudo o que circunda tecnologicamente os produtos disponíveis no seu mercado. Se ele fosse informado que a solução para os seus problemas estaria em usar inteligência artificial, muito possivelmente seria induzido a erro. Afinal, ele pode equivocadamente imaginar do que se trata. Em contraste, o mesmo advogado não seria afetado se recebesse um conselho para utilizar uma solução com base em “banco de grafos”.
Nomes técnicos não comunicam e também não vendem. Nesse sentido, a inteligência artificial é vítima dessa infeliz coincidência. Para escapar ao novo hype, será necessário que nossa comunidade se dedique a compreender o que realmente a inteligência artificial é e quais suas reais possibilidades. Do contrário, continuaremos na sucessão de hypes, que mais alienam do que informam.
Este post faz parte de uma série. Antes de ler, veja o post anterior.
Convencidos da utilidade de um classificador de decisões judiciais quanto ao seu desfecho, passamos a organizar os dados. O primeiro passo foi baixar os acórdãos do STF e elaborar um modelo relacional para estruturar as informações. Basicamente era necessário construir um acervo e os campos nos quais cada acórdão seria fragmentado.
Nesse propósito, foi elaborado um programa de computador capaz de fazer o download e guardar os dados separados por acórdão, classe, número e, especialmente, com identificação da respectiva certidão de julgamento. Como parece intuitivo, essa é uma fase que demanda um enorme investimento em termos de tecnologia, aliado a atenção da equipe de juristas para separar as partes do acórdão a serem consultadas para a posterior classificação das decisões.
Separamos o essencial de forma bastante detalhada e guardamos algumas informações em estado bruto para posterior revisão. Dividimos a equipe em responsáveis por ler as certidões de julgamento de cada classe processual, iniciando pelas seguintes: mandado de segurança, reclamação, habeas corpus e recurso extraordinário. Resolvemos não trabalhar com outros processos, pois eram em número muito pequeno.
Enquanto as primeiras classes tinham poucos milhares de acórdãos cada uma, os recursos extraordinários foram avaliados em volume muito maior. Aliás, seu maior volume sempre foi um obstáculo a pesquisas empíricas de controle difuso de constitucionalidade, pois é preciso mais organização para trabalhar decisões na casa de dezenas de milhares de linhas. Realmente não é algo que um pesquisador apenas possa fazer.
Organizamos esses dados em uma plataforma de anotação, de tal modo que, em conjunto, a equipe de juristas tivesse condições de propor um modelo inicial de classificação de resultados dos acórdãos. Depois de muita discussão sobre as opções de construir um classificador mais complexo ou mais simples, surgiu o seguinte modelo:
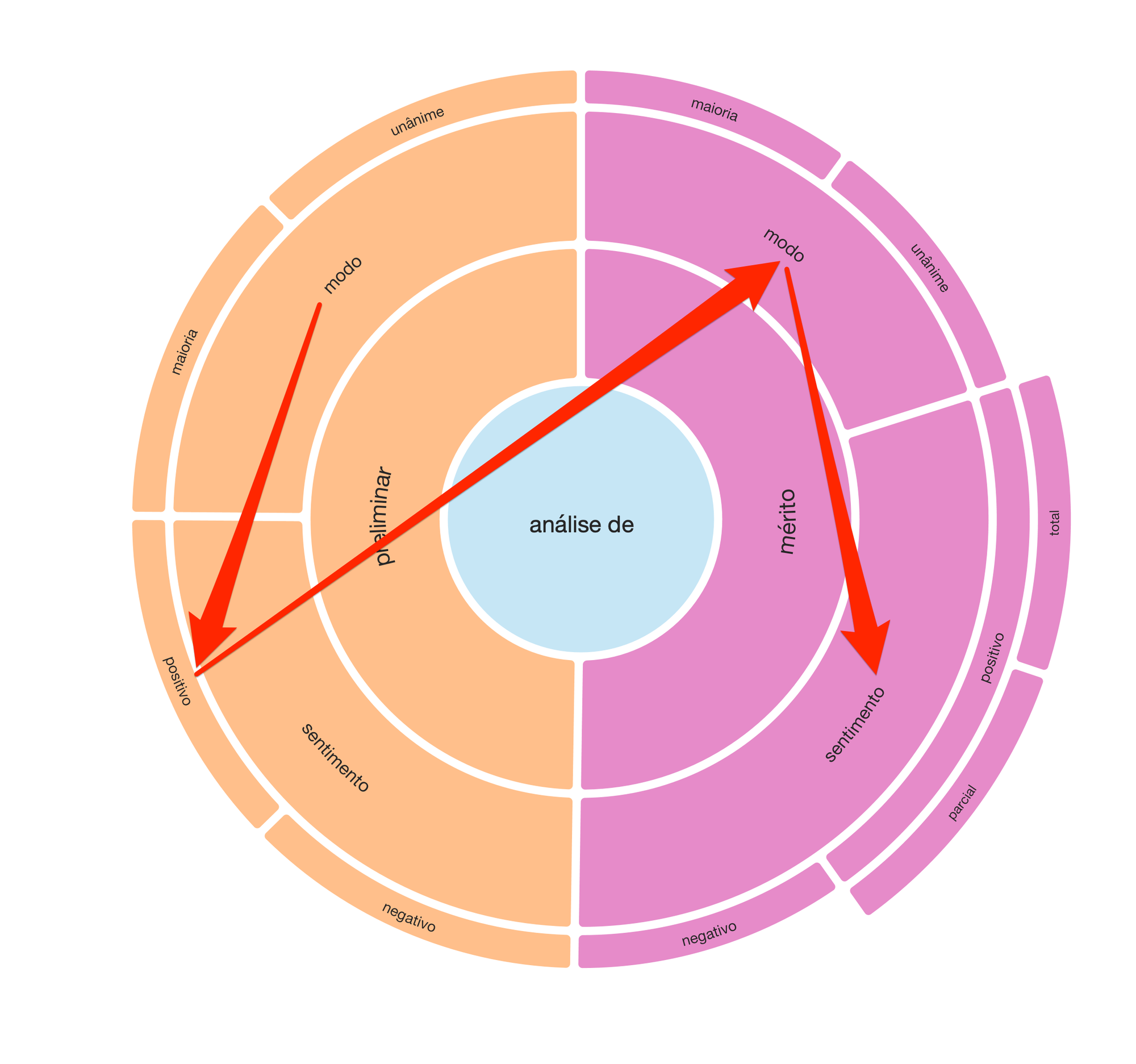
Decidimos, assim, realizar um juízo preliminar (por maioria ou unanimidade), o qual, se positivo, levaria à avaliação do mérito. Do mesmo modo, o juízo de mérito foi bipartido em seus modos (maioria ou unanimidade) e respectivos desfechos: positivo e negativo. Por fim, especificamente para o juízo de mérito positivo, dividimos também a avaliação pela abrangência do provimento: total ou parcial.
A partir dessa sequência de juízos, ilustrada no radial, teríamos condição de ampliar a amostra para a casa das dezenas de milhares de acórdãos de forma consistente.
O que faltava apenas era uma plataforma de anotação que fosse capaz de abrigar esse trabalho, permitindo o acesso simultâneo dos pesquisadores ao acervo. Transferimos então o acervo para uma infraestrutura em nuvem dotada dessa capacidade e iniciamos a classificação. Um exemplo simplificado de como os dados estão estruturados, tomando como exemplo os mandados de segurança, é o seguinte:
Embora algumas partes da tabela tenham sido omitidas (o que preserva a originalidade da pesquisa até sua publicaçãoo), já é possível notar a estrutura que montamos para anotação do modo (maioria ou unânime). A título de exemplo, no caso dos recursos extraordinários, classificamos 3.972 acórdãos como unânimes, tendo as seguintes variações: unanimamente, unanimidade, unânime, acordo de votos e decisão uniforme.
Isso significa que, nesse ponto, nossa base de dados passou a contar com quase quatro mil vínculos devidamente etiquetados. São processos reais, dos quais conhecemos diversos atributos. A mesma filosofia vale para o vocabulário presente no acervo para classificar o desfecho (positivo ou negativo) do julgado. A diferença é que existem não apenas cinco, mas centenas de variações de palavras utilizadas para traduzir o desfecho de um acórdão.
Como sabemos muito sobre cada um desses processos, torna-se possível treinar uma máquina para que, reconhecendo um padrão, sugira uma etiqueta contemplando o modo (por exemplo, unânime) e o desfecho (por exemplo, desfavorável) diante um novo acórdão que venha a ser prolatado. Assim, ensinamos a máquina classificar rapidamente milhares de novas decisões, a partir da curadoria realizada pelos nossos pesquisadores.
O aprendizado de máquina em si também não é uma tarefa trivial e será objeto de um novo post. Tratamos até agora apenas da prepração dos dados, que é uma etapa essencial e frequentemente negligenciada. Sem dados devidamente organizados, não é possível desenvolver soluções de inteligência artificial.
Este post faz parte de uma série. Antes de ler, veja o post anterior.
Convencidos da utilidade de um classificador de decisões judiciais quanto ao seu desfecho, passamos a organizar os dados. O primeiro passo foi baixar os acórdãos do STF e elaborar um modelo relacional para estruturar as informações. Basicamente era necessário construir um acervo e os campos nos quais cada acórdão seria fragmentado.
Nesse propósito, foi elaborado um programa de computador capaz de fazer o download e guardar os dados separados por acórdão, classe, número e, especialmente, com identificação da respectiva certidão de julgamento. Como parece intuitivo, essa é uma fase que demanda um enorme investimento em termos de tecnologia, aliado a atenção da equipe de juristas para separar as partes do acórdão a serem consultadas para a posterior classificação das decisões.
Separamos o essencial de forma bastante detalhada e guardamos algumas informações em estado bruto para posterior revisão. Dividimos a equipe em responsáveis por ler as certidões de julgamento de cada classe processual, iniciando pelas seguintes: mandado de segurança, reclamação, habeas corpus e recurso extraordinário. Resolvemos não trabalhar com outros processos, pois eram em número muito pequeno.
Enquanto as primeiras classes tinham poucos milhares de acórdãos cada uma, os recursos extraordinários foram avaliados em volume muito maior. Aliás, seu maior volume sempre foi um obstáculo a pesquisas empíricas de controle difuso de constitucionalidade, pois é preciso mais organização para trabalhar decisões na casa de dezenas de milhares de linhas. Realmente não é algo que um pesquisador apenas possa fazer.
Organizamos esses dados em uma plataforma de anotação, de tal modo que, em conjunto, a equipe de juristas tivesse condições de propor um modelo inicial de classificação de resultados dos acórdãos. Depois de muita discussão sobre as opções de construir um classificador mais complexo ou mais simples, surgiu o seguinte modelo:
Decidimos, assim, realizar um juízo preliminar (por maioria ou unanimidade), o qual, se positivo, levaria à avaliação do mérito. Do mesmo modo, o juízo de mérito foi bipartido em seus modos (maioria ou unanimidade) e respectivos desfechos: positivo e negativo. Por fim, especificamente para o juízo de mérito positivo, dividimos também a avaliação pela abrangência do provimento: total ou parcial.
A partir dessa sequência de juízos, ilustrada no radial, teríamos condição de ampliar a amostra para a casa das dezenas de milhares de acórdãos de forma consistente.
O que faltava apenas era uma plataforma de anotação que fosse capaz de abrigar esse trabalho, permitindo o acesso simultâneo dos pesquisadores ao acervo. Transferimos então o acervo para uma infraestrutura em nuvem dotada dessa capacidade e iniciamos a classificação. Um exemplo simplificado de como os dados estão estruturados, tomando como exemplo os mandados de segurança, é o seguinte:
Embora algumas partes da tabela tenham sido omitidas (o que preserva a originalidade da pesquisa até sua publicaçãoo), já é possível notar a estrutura que montamos para anotação do modo (maioria ou unânime). A título de exemplo, no caso dos recursos extraordinários, classificamos 3.972 acórdãos como unânimes, tendo as seguintes variações: unanimamente, unanimidade, unânime, acordo de votos e decisão uniforme.
Isso significa que, nesse ponto, nossa base de dados passou a contar com quase quatro mil vínculos devidamente etiquetados. São processos reais, dos quais conhecemos diversos atributos. A mesma filosofia vale para o vocabulário presente no acervo para classificar o desfecho (positivo ou negativo) do julgado. A diferença é que existem não apenas cinco, mas centenas de variações de palavras utilizadas para traduzir o desfecho de um acórdão.
Como sabemos muito sobre cada um desses processos, torna-se possível treinar uma máquina para que, reconhecendo um padrão, sugira uma etiqueta contemplando o modo (por exemplo, unânime) e o desfecho (por exemplo, desfavorável) diante um novo acórdão que venha a ser prolatado. Assim, ensinamos a máquina classificar rapidamente milhares de novas decisões, a partir da curadoria realizada pelos nossos pesquisadores.
O aprendizado de máquina em si também não é uma tarefa trivial e será objeto de um novo post. Tratamos até agora apenas da prepração dos dados, que é uma etapa essencial e frequentemente negligenciada. Sem dados devidamente organizados, não é possível desenvolver soluções de inteligência artificial.
Os profissionais do Direito consomem diversos tipos de informação jurídica, sendo duas as principais: a lei e a jurisprudência. A lei é uma norma abstrata, ou seja, não foi aplicada a um caso concreto. Já a jurisprudência é uma norma concreta, feita para solucionar um caso submetido ao Poder Judiciário.
Embora seja relativamente fácil conhecer as leis, pois elas estão publicadas em repositórios oficiais, é muito mais complexo conhecer a jurisprudência. O repositório legislativo mais utilizado é o do Planalto e ele ilustra bem como são organizadas e consumidas as várias formas de legislação federal no Brasil. Em contraste, existem diversos tribunais e cada um é responsável por publicar sua própria jurisprudência.
De uma forma geral, os tribunais tratam esses dados como documentos em linguagem natural, com uma camada adicional relativamente limitada de metadados.
Assim, existem poucos filtros para acessar essa informação, por exemplo: a data do julgado, o nome do julgador, o órgão ao qual pertence esse julgador, o nome e a posição de cada parte no processo, etc. Não encontramos, contudo, nenhum repositório público organizado em torno da dimensão do resultado do julgado, se favorável ou desfavorável seu desfecho.
Consideremos o seguinte caso de uso:
É possível imaginar que um advogado de um banco faça uma pesquisa de jurisprudência em determinado tribunal para avaliar a chance de êxito de uma nova demanda.
Tal como está indexada a base de julgados do STF, ele consegue, com alguma facilidade, encontrar casos concretos que trataram de um determinado tema. Contudo, o advogado tem muita dificuldade em encontrar, dentro desse tema, quais foram os casos vencidos por bancos e nos quais os mesmos bancos foram derrotados.
A utilidade de desenvolver uma solução que compreenda quais são os casos favoráveis e desfavoráveis está em viabilizar uma consulta agregada também por essa dimensão, referente ao resultado do julgado. Afinal, a consulta profissional tem quase sempre um lado interessado, de tal modo que saber qual o desfecho do caso é uma informação muito importante para a vida prática dos profissionais do Direito.
Nas próximas semanas, publicaremos por aqui a jornada de vários dos pesquisadores do DireitoTec, dedicados a mapear dezenas de milhares de julgados do STF. Isso permitirá criar uma base para treinamento de inteligência artificial, de tal modo que seja possível classificar automaticamente o desfecho de um acórdão. Que tal? Parece promissor?
Este post faz parte de uma série. Veja o post seguinte.
Os profissionais do Direito consomem diversos tipos de informação jurídica, sendo duas as principais: a lei e a jurisprudência. A lei é uma norma abstrata, ou seja, não foi aplicada a um caso concreto. Já a jurisprudência é uma norma concreta, feita para solucionar um caso submetido ao Poder Judiciário.
Embora seja relativamente fácil conhecer as leis, pois elas estão publicadas em repositórios oficiais, é muito mais complexo conhecer a jurisprudência. O repositório legislativo mais utilizado é o do Planalto e ele ilustra bem como são organizadas e consumidas as várias formas de legislação federal no Brasil. Em contraste, existem diversos tribunais e cada um é responsável por publicar sua própria jurisprudência.
De uma forma geral, os tribunais tratam esses dados como documentos em linguagem natural, com uma camada adicional relativamente limitada de metadados.
Assim, existem poucos filtros para acessar essa informação, por exemplo: a data do julgado, o nome do julgador, o órgão ao qual pertence esse julgador, o nome e a posição de cada parte no processo, etc. Não encontramos, contudo, nenhum repositório público organizado em torno da dimensão do resultado do julgado, se favorável ou desfavorável seu desfecho.
Consideremos o seguinte caso de uso:
É possível imaginar que um advogado de um banco faça uma pesquisa de jurisprudência em determinado tribunal para avaliar a chance de êxito de uma nova demanda.
Tal como está indexada a base de julgados do STF, ele consegue, com alguma facilidade, encontrar casos concretos que trataram de um determinado tema. Contudo, o advogado tem muita dificuldade em encontrar, dentro desse tema, quais foram os casos vencidos por bancos e nos quais os mesmos bancos foram derrotados.
A utilidade de desenvolver uma solução que compreenda quais são os casos favoráveis e desfavoráveis está em viabilizar uma consulta agregada também por essa dimensão, referente ao resultado do julgado. Afinal, a consulta profissional tem quase sempre um lado interessado, de tal modo que saber qual o desfecho do caso é uma informação muito importante para a vida prática dos profissionais do Direito.
Nas próximas semanas, publicaremos por aqui a jornada de vários dos pesquisadores do DireitoTec, dedicados a mapear dezenas de milhares de julgados do STF. Isso permitirá criar uma base para treinamento de inteligência artificial, de tal modo que seja possível classificar automaticamente o desfecho de um acórdão. Que tal? Parece promissor?
Este post faz parte de uma série. Veja o post seguinte.