inteligência artificial
O CEPEJ (Comissão Europeia para Eficiência da Justiça) é uma das principais fontes para quem gosta de direito comparado. Em sua última plenária (08/12/2021), foi aprovado um Plano de Ação Quadrienal, com o objetivo de adotar novas tecnologias para o aprimoramento da Justiça.
O plano pretende conciliar, com o auxílio da tecnologia, a efetividade na prestação com a qualidade dos serviços públicos jurisdicionais. Os eixos que suportam essa estratégia são transparência, colaboração, valorização das pessoas, acessibilidade, racionalidade, responsabilidade e responsividade.
Paralelamente, nessa mesma oportunidade, o CEPEJ revisou seu planejamento para a promoção do uso ético da inteligência artificial (IA) pelo Judiciário. O trabalho atualmente revisto teve início em 2018, quando foram estabelecidos cinco pontos principais para adoção de soluções de IA: respeito aos direitos fundamentais; não discriminação; qualidade e segurança dos dados; transparência, imparcialidade e justiça; bem como a independência do usuário.
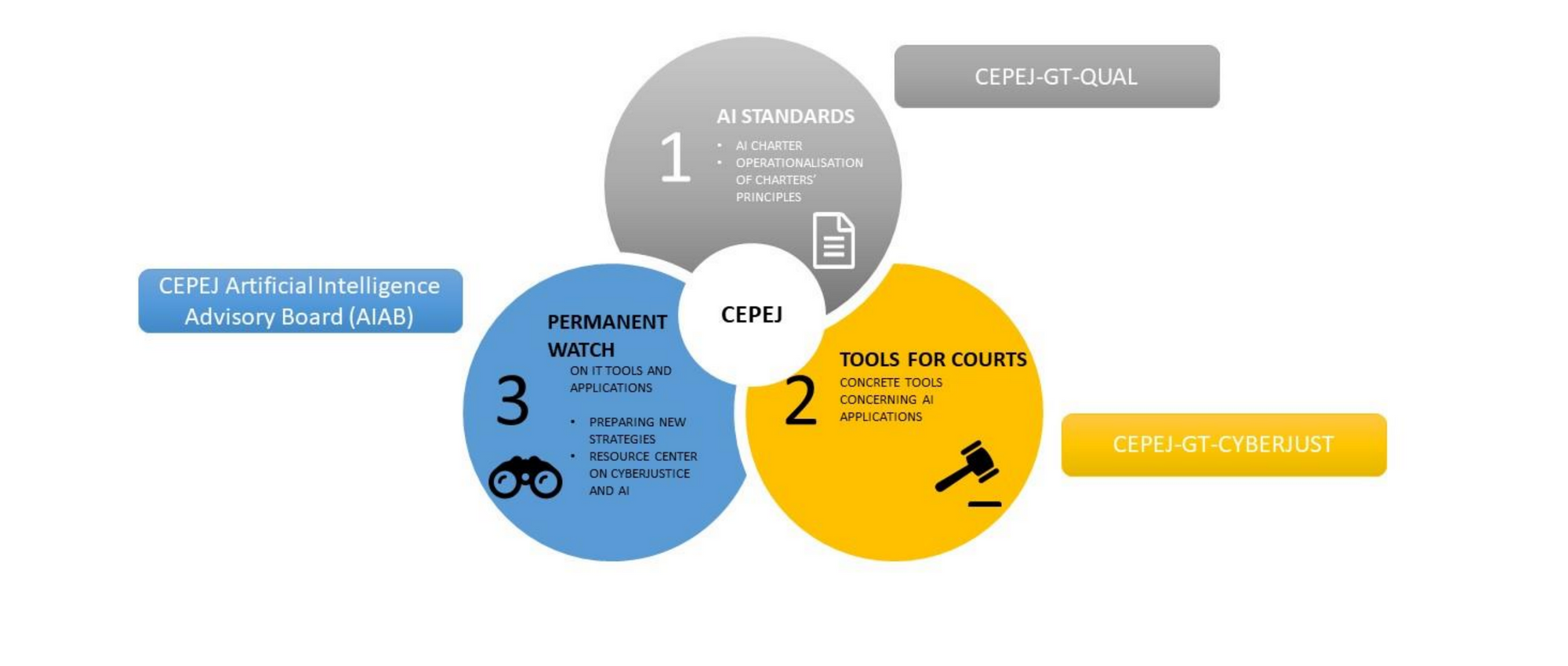
Desde o início, o CEPEJ demonstrou estar ciente de que não existe solução mágica para o assunto, especialmente considerando seu pioneirismo na tentativa de estabelecer condições para que a IA avance respeitando os direitos humanos. Passados dois anos, o mesmo grupo de trabalho inicial teve como propósito avaliar a viabilidade dessa missão, tendo apresentado seu relatório em 2020.
Em meados de 2021, foi apresentada a primeira versão do planejamento para certificação das soluções de IA. Mas, tendo em conta as discussões instauradas e a dificuldade em criar uma solução que respeitasse a visão de diversos países, a conclusão do trabalho foi postergado para a reunião plenária de fim de ano.
O objetivo dessa iniciativa (movida pelo Conselho da Europa), a despeito de seu estágio inicial, pretende regulamentar as soluções de IA de alto risco. Como são muitos países envolvidos, é natural que a Europa não avance tão rapidamente nesse ponto. A título de exemplo, o Brasil já conta como regulamentação da matéria, inclusive com diretrizes fixadas pelo CNJ. Nesse ponto podemos dizer que estamos mais adiantados que a Europa.
IA na Folha de São Paulo: matéria ou publi?
Comentário sobre as matérias da Folha de São Paulo sobre aplicações de inteligência artificial no mundo do Direito.
A Folha de São Paulo publicou recentemente uma série de matérias sobre inteligência artificial. Apesar do anúncio incomum, o artigo não foi promovido como um publieditorial. Este é o cabeçalho da matéria de 20/02/20:
E este é seu rodapé:
Ou seja, pode até não ser um publieditorial, mas é uma coluna patrocinada com certeza. Isso demonstra que a Folha está engajada em uma atividade educativa (louvável), o que não nos desonera de considerar os patrocinadores quando encontramos alguma notícia que nos seja especialmente interessante.
Muito bem. Nesse contexto, a Folha publicou também em 10/03/20: "Inteligência artificial atua como juiz, muda estratégia de advogado e promove estagiário".

Como não sei se meu comentário seria autorizado no sistema da Folha, deixou aqui meu roteiro de leitura do artigo. Espero que, com essas advertências, a matéria se torne mais informativa sobre o uso da Inteligência Artificial (IA) no Direito:
- Folha: "Segundo a versão mais recente do "Justiça em Números" (...), 108,3 milhões de causas tiveram início em versão digital de 2008 a 2018". Eu: Isso não é muito relevante para IA, uma vez que o que foi transferido para a plataforma digital foi a tramitação. Os autos continuam a ser PDF normais, os quais não fornecem facilmente o tipo de dados que sistemas inteligentes consomem.
- Folha: "Ilustração de Diana, nome dado ao programa de inteligência artifical do escritório Lee, Brock e Camargo Advogados". Eu: Sério?
Folha: "Macêdo utiliza no dia a dia o sistema, batizado de Elis (no Judiciário de Pernambuco)". Eu: Tudo bem que batizar coisas seja divertido. Mas será que precisamos de mais um robô em 2020?
Folha: "No texto da própria decisão está dizendo que foi Elis quem fez, para permitir transparência no processo, para que se saiba o que está sendo usado." Eu: Você coloca na decisão que foi feito em Word ou máquina de escrever?
Folha: "Segundo Juliana Neiva, secretária de Tecnologia da Informação e Comunicação do tribunal, o desenvolvimento da IA teve custo zero para a corte, pois foi desenvolvido por servidores do próprio órgão." Eu: Os servidores são custo zero?
Folha: "O STJ quer ir mais longe no uso da tecnologia e relata que já está em andamento o projeto Sócrates 2, no qual a ideia é avançar para que a IA em breve forneça de forma organizada aos juízes todos os elementos necessários para o julgamento das causas, como a descrição das teses das partes e as principais decisões já tomadas pelo tribunal em relação ao assunto do processo." Eu: Será que IA é a melhor (ou única) forma de fazer isso?
Folha: "Para lidar com esse problema, o escritório Lee, Brock e Camargo Advogados (LBCA) desenvolveu um aplicativo ligado a um sistema de IA. O mecanismo possibilita levantar, logo após conhecer quem são os depoentes da parte adversária, tudo o que essas testemunhas já disseram em outros processos, afirma Solano de Camargo, sócio fundador do LBCA." Eu: Alguém acha que precisa de IA para isso? Será que esse é realmente um problema central para um escritório de contencioso de massa? O importante não é saber o que o a testemunha falará sobre os fatos daquele determinado processo?
Folha: "O sistema de IA do escritório foi batizado de Diana e já consumiu investimentos de R$ 3 milhões nos últimos anos, diz Camargo. O custo inclui a implantação de um laboratório de tecnologia interno que conta com 41 integrantes." Eu: Com 41 integrantes, você nem precisa de inteligência artificial. Todo o sentido da tecnologia é dar mais produtividade para que você possa ter equipes pequenas.
Folha: "Exemplos de uso: O escritório Lee, Brock e Camargo Advogados (LBCA), de São Paulo, desenvolveu um sistema de IA e um aplicativo conectado a ele. Os advogados da banca podem abrir o aplicativo no decorrer de audiências e usar as análises do software para identificar, por exemplo, contradições de uma testemunha enquanto ela fala ao juiz" Eu: Preciso escrever um post sobre isso.
A Folha de São Paulo é um jornal muito importante e, no meu modo de ver, deveria ser mais seletiva em suas publicações. É natural que um jornal tenha anunciantes. Não é normal, contudo, desinformar dessa maneira. Seria bem legal que a Folha desse sequência na matéria de uma maneira menos capturada. Ou então deixasse mais claro quem é o anunciante, sob pena de se tornar apenas mais uma página na internet.
No último British Legal Technology Forum, realizado em Londres nesta semana, foram discutidos vários assuntos relacionados a inteligência artificial aplicada ao direito. O blog Artificial Lawyer esteve lá e publicou uma reflexão interessante sobre uma nova onda de opiniões sobre inteligência artificial, a qual chamou de “Post-Hype AI Hype”.
Para quem não está familiarizado, hype é algo exagerado e com uma conotação negativa. Está em hype qualquer assunto que esteja dando o que falar, que esteja na moda, mas que ao mesmo tempo não tenha fundamento comprovado. No contexto da tecnologia, algo que esteja em hype traz consigo um grande receio de que o estado atual da tecnologia não seja suficiente para solucionar os problemas que se propõe a enfrentar.
O movimento atual, diagnosticado nesta semana ainda, sustenta que o ciclo de expectativas exacerbadas sobre o potencial da inteligência artificial estaria chegando ao fim. No lugar de discutir um futuro distante, esse movimento tem como objetivo refletir sobre aplicações práticas e imediatas, as quais geralmente demandam tecnologias já sedimentadas. Ou seja, formou-se um novo ciclo no setor contra a inteligência artificial - mas que não deixa de ser igualmente uma espécie de hype.
No fundo, temos agora um novo hype assumindo o lugar do outro. Nenhum deles foi deliberadamente criado, pois foi composto de uma soma de vozes que realmente acreditavam naquilo que prometiam como solução de todos os problemas. Hoje, recauchutado, o hype se organiza para evitar a terminologia até então celebrada, mas isso não é algo que venha sem qualquer dificuldade. Afinal, ainda que de forma imprecisa, inteligência artificial já é um termo incorporado ao vocabulário corrente. De toda forma, isso viabilizou a comunicação até agora.
Debater assuntos conexos falando de aprendizado de máquina, processamento de linguagem natural, classificação automática de decisões, entre outros termos, é algo que demandaria muito mais energia. Trata-se de algo que certamente não é do interesse das empresas que utilizam o jargão apenas como marketing, sem nenhum compromisso em embarcar a tecnologia que anunciam em seus produtos.
Parece que o termo inteligência artificial perdeu o seu frescor. Ao mesmo tempo - e não por acaso - algumas de suas promessas simplesmente não foram concretizadas para o mercado jurídico. Vivemos uma ressaca semelhante àquela que recentemente passou a medicina, pois a inteligência artificial não descobriu a “cura do câncer”. E nós continuamos sem a “cura para os processos”.
De ciclo em ciclo, o hype se revela como o próprio modo de ser de comunidades profissionais com domínio limitado sobre o que deveria ser discutido e compreendido em profundidade. Uma vez instalado, ele não se dissolve facilmente, sendo sucedido por uma nova promessa que também não se realizará. Esse encadeamento de promessas e frustrações é típico dos setores que consomem tecnologia, sem que tenham as ferramentas para sua compreensão total.
Assim, o hype é consequência da nossa própria falta de domínio técnico, da nossa consequente superficialidade nesse campo. São ingredientes adicionais o interesse de pessoas de alimentarem o hype, por exemplo, um conferencista que reafirme seu suposto saber ou empresas que vendam o hype, pois elas funcionam na lógica de uma comunicação imediata e facilitada.
Os elementos finais são as palavras inteligência e artificial, que transmitem um sentido bastante equívoco daquilo que realmente são quando utilizadas em conjunto. Seria melhor que essa tecnologia não tivesse seu conteúdo induzido por vocábulos que achamos que compreendemos, pois fazem parte da nossa linguagem em outros contextos.
Embora um advogado entenda plenamente os desafios jurídicos do seu trabalho diário, dificilmente compreenderia tudo o que circunda tecnologicamente os produtos disponíveis no seu mercado. Se ele fosse informado que a solução para os seus problemas estaria em usar inteligência artificial, muito possivelmente seria induzido a erro. Afinal, ele pode equivocadamente imaginar do que se trata. Em contraste, o mesmo advogado não seria afetado se recebesse um conselho para utilizar uma solução com base em “banco de grafos”.
Nomes técnicos não comunicam e também não vendem. Nesse sentido, a inteligência artificial é vítima dessa infeliz coincidência. Para escapar ao novo hype, será necessário que nossa comunidade se dedique a compreender o que realmente a inteligência artificial é e quais suas reais possibilidades. Do contrário, continuaremos na sucessão de hypes, que mais alienam do que informam.
Este post faz parte de uma série. Antes de ler, veja o post anterior.
Convencidos da utilidade de um classificador de decisões judiciais quanto ao seu desfecho, passamos a organizar os dados. O primeiro passo foi baixar os acórdãos do STF e elaborar um modelo relacional para estruturar as informações. Basicamente era necessário construir um acervo e os campos nos quais cada acórdão seria fragmentado.
Nesse propósito, foi elaborado um programa de computador capaz de fazer o download e guardar os dados separados por acórdão, classe, número e, especialmente, com identificação da respectiva certidão de julgamento. Como parece intuitivo, essa é uma fase que demanda um enorme investimento em termos de tecnologia, aliado a atenção da equipe de juristas para separar as partes do acórdão a serem consultadas para a posterior classificação das decisões.
Separamos o essencial de forma bastante detalhada e guardamos algumas informações em estado bruto para posterior revisão. Dividimos a equipe em responsáveis por ler as certidões de julgamento de cada classe processual, iniciando pelas seguintes: mandado de segurança, reclamação, habeas corpus e recurso extraordinário. Resolvemos não trabalhar com outros processos, pois eram em número muito pequeno.
Enquanto as primeiras classes tinham poucos milhares de acórdãos cada uma, os recursos extraordinários foram avaliados em volume muito maior. Aliás, seu maior volume sempre foi um obstáculo a pesquisas empíricas de controle difuso de constitucionalidade, pois é preciso mais organização para trabalhar decisões na casa de dezenas de milhares de linhas. Realmente não é algo que um pesquisador apenas possa fazer.
Organizamos esses dados em uma plataforma de anotação, de tal modo que, em conjunto, a equipe de juristas tivesse condições de propor um modelo inicial de classificação de resultados dos acórdãos. Depois de muita discussão sobre as opções de construir um classificador mais complexo ou mais simples, surgiu o seguinte modelo:
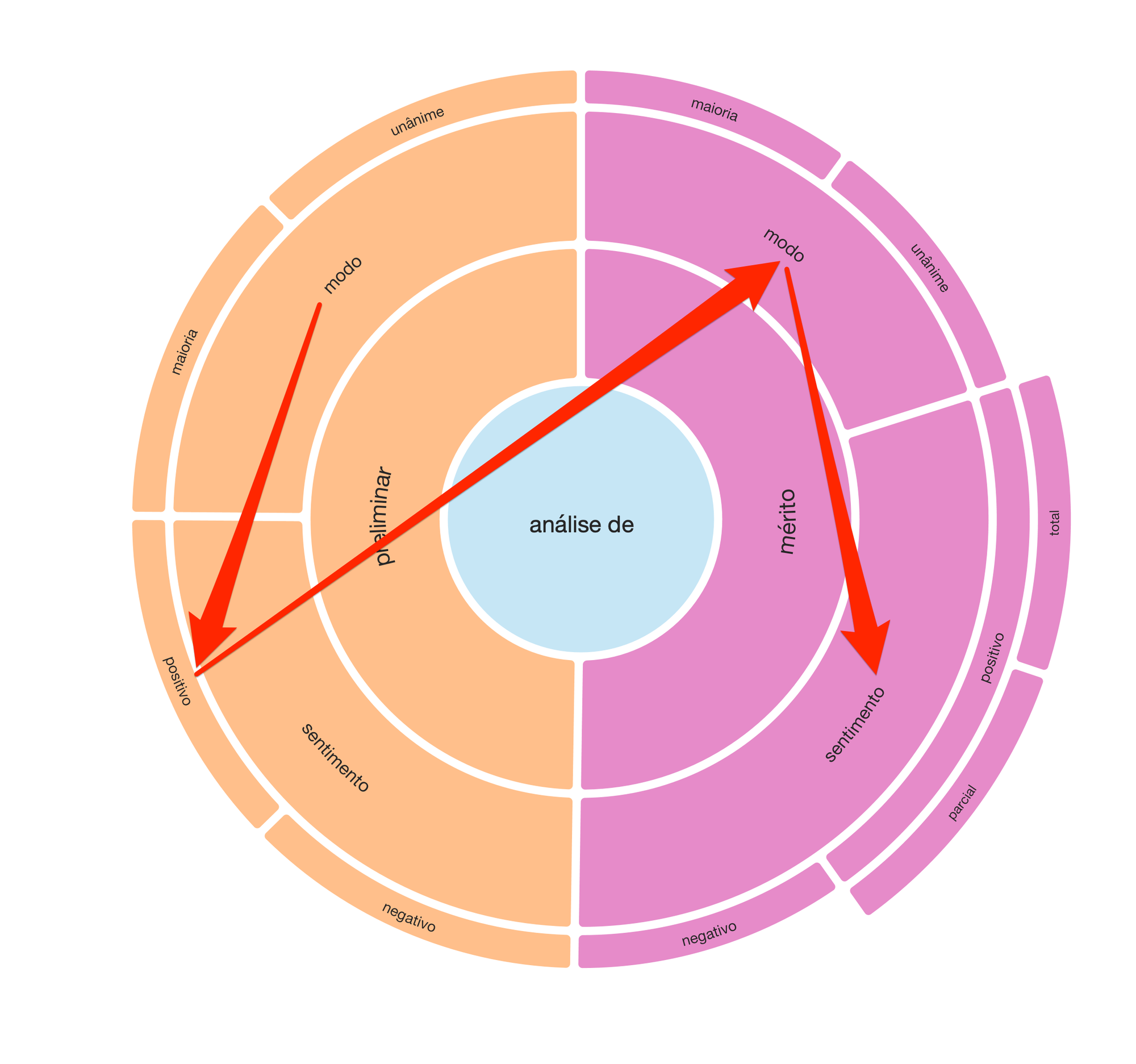
Decidimos, assim, realizar um juízo preliminar (por maioria ou unanimidade), o qual, se positivo, levaria à avaliação do mérito. Do mesmo modo, o juízo de mérito foi bipartido em seus modos (maioria ou unanimidade) e respectivos desfechos: positivo e negativo. Por fim, especificamente para o juízo de mérito positivo, dividimos também a avaliação pela abrangência do provimento: total ou parcial.
A partir dessa sequência de juízos, ilustrada no radial, teríamos condição de ampliar a amostra para a casa das dezenas de milhares de acórdãos de forma consistente.
O que faltava apenas era uma plataforma de anotação que fosse capaz de abrigar esse trabalho, permitindo o acesso simultâneo dos pesquisadores ao acervo. Transferimos então o acervo para uma infraestrutura em nuvem dotada dessa capacidade e iniciamos a classificação. Um exemplo simplificado de como os dados estão estruturados, tomando como exemplo os mandados de segurança, é o seguinte:
Embora algumas partes da tabela tenham sido omitidas (o que preserva a originalidade da pesquisa até sua publicaçãoo), já é possível notar a estrutura que montamos para anotação do modo (maioria ou unânime). A título de exemplo, no caso dos recursos extraordinários, classificamos 3.972 acórdãos como unânimes, tendo as seguintes variações: unanimamente, unanimidade, unânime, acordo de votos e decisão uniforme.
Isso significa que, nesse ponto, nossa base de dados passou a contar com quase quatro mil vínculos devidamente etiquetados. São processos reais, dos quais conhecemos diversos atributos. A mesma filosofia vale para o vocabulário presente no acervo para classificar o desfecho (positivo ou negativo) do julgado. A diferença é que existem não apenas cinco, mas centenas de variações de palavras utilizadas para traduzir o desfecho de um acórdão.
Como sabemos muito sobre cada um desses processos, torna-se possível treinar uma máquina para que, reconhecendo um padrão, sugira uma etiqueta contemplando o modo (por exemplo, unânime) e o desfecho (por exemplo, desfavorável) diante um novo acórdão que venha a ser prolatado. Assim, ensinamos a máquina classificar rapidamente milhares de novas decisões, a partir da curadoria realizada pelos nossos pesquisadores.
O aprendizado de máquina em si também não é uma tarefa trivial e será objeto de um novo post. Tratamos até agora apenas da prepração dos dados, que é uma etapa essencial e frequentemente negligenciada. Sem dados devidamente organizados, não é possível desenvolver soluções de inteligência artificial.
Este post faz parte de uma série. Antes de ler, veja o post anterior.
Convencidos da utilidade de um classificador de decisões judiciais quanto ao seu desfecho, passamos a organizar os dados. O primeiro passo foi baixar os acórdãos do STF e elaborar um modelo relacional para estruturar as informações. Basicamente era necessário construir um acervo e os campos nos quais cada acórdão seria fragmentado.
Nesse propósito, foi elaborado um programa de computador capaz de fazer o download e guardar os dados separados por acórdão, classe, número e, especialmente, com identificação da respectiva certidão de julgamento. Como parece intuitivo, essa é uma fase que demanda um enorme investimento em termos de tecnologia, aliado a atenção da equipe de juristas para separar as partes do acórdão a serem consultadas para a posterior classificação das decisões.
Separamos o essencial de forma bastante detalhada e guardamos algumas informações em estado bruto para posterior revisão. Dividimos a equipe em responsáveis por ler as certidões de julgamento de cada classe processual, iniciando pelas seguintes: mandado de segurança, reclamação, habeas corpus e recurso extraordinário. Resolvemos não trabalhar com outros processos, pois eram em número muito pequeno.
Enquanto as primeiras classes tinham poucos milhares de acórdãos cada uma, os recursos extraordinários foram avaliados em volume muito maior. Aliás, seu maior volume sempre foi um obstáculo a pesquisas empíricas de controle difuso de constitucionalidade, pois é preciso mais organização para trabalhar decisões na casa de dezenas de milhares de linhas. Realmente não é algo que um pesquisador apenas possa fazer.
Organizamos esses dados em uma plataforma de anotação, de tal modo que, em conjunto, a equipe de juristas tivesse condições de propor um modelo inicial de classificação de resultados dos acórdãos. Depois de muita discussão sobre as opções de construir um classificador mais complexo ou mais simples, surgiu o seguinte modelo:
Decidimos, assim, realizar um juízo preliminar (por maioria ou unanimidade), o qual, se positivo, levaria à avaliação do mérito. Do mesmo modo, o juízo de mérito foi bipartido em seus modos (maioria ou unanimidade) e respectivos desfechos: positivo e negativo. Por fim, especificamente para o juízo de mérito positivo, dividimos também a avaliação pela abrangência do provimento: total ou parcial.
A partir dessa sequência de juízos, ilustrada no radial, teríamos condição de ampliar a amostra para a casa das dezenas de milhares de acórdãos de forma consistente.
O que faltava apenas era uma plataforma de anotação que fosse capaz de abrigar esse trabalho, permitindo o acesso simultâneo dos pesquisadores ao acervo. Transferimos então o acervo para uma infraestrutura em nuvem dotada dessa capacidade e iniciamos a classificação. Um exemplo simplificado de como os dados estão estruturados, tomando como exemplo os mandados de segurança, é o seguinte:
Embora algumas partes da tabela tenham sido omitidas (o que preserva a originalidade da pesquisa até sua publicaçãoo), já é possível notar a estrutura que montamos para anotação do modo (maioria ou unânime). A título de exemplo, no caso dos recursos extraordinários, classificamos 3.972 acórdãos como unânimes, tendo as seguintes variações: unanimamente, unanimidade, unânime, acordo de votos e decisão uniforme.
Isso significa que, nesse ponto, nossa base de dados passou a contar com quase quatro mil vínculos devidamente etiquetados. São processos reais, dos quais conhecemos diversos atributos. A mesma filosofia vale para o vocabulário presente no acervo para classificar o desfecho (positivo ou negativo) do julgado. A diferença é que existem não apenas cinco, mas centenas de variações de palavras utilizadas para traduzir o desfecho de um acórdão.
Como sabemos muito sobre cada um desses processos, torna-se possível treinar uma máquina para que, reconhecendo um padrão, sugira uma etiqueta contemplando o modo (por exemplo, unânime) e o desfecho (por exemplo, desfavorável) diante um novo acórdão que venha a ser prolatado. Assim, ensinamos a máquina classificar rapidamente milhares de novas decisões, a partir da curadoria realizada pelos nossos pesquisadores.
O aprendizado de máquina em si também não é uma tarefa trivial e será objeto de um novo post. Tratamos até agora apenas da prepração dos dados, que é uma etapa essencial e frequentemente negligenciada. Sem dados devidamente organizados, não é possível desenvolver soluções de inteligência artificial.
Os profissionais do Direito consomem diversos tipos de informação jurídica, sendo duas as principais: a lei e a jurisprudência. A lei é uma norma abstrata, ou seja, não foi aplicada a um caso concreto. Já a jurisprudência é uma norma concreta, feita para solucionar um caso submetido ao Poder Judiciário.
Embora seja relativamente fácil conhecer as leis, pois elas estão publicadas em repositórios oficiais, é muito mais complexo conhecer a jurisprudência. O repositório legislativo mais utilizado é o do Planalto e ele ilustra bem como são organizadas e consumidas as várias formas de legislação federal no Brasil. Em contraste, existem diversos tribunais e cada um é responsável por publicar sua própria jurisprudência.
De uma forma geral, os tribunais tratam esses dados como documentos em linguagem natural, com uma camada adicional relativamente limitada de metadados.
Assim, existem poucos filtros para acessar essa informação, por exemplo: a data do julgado, o nome do julgador, o órgão ao qual pertence esse julgador, o nome e a posição de cada parte no processo, etc. Não encontramos, contudo, nenhum repositório público organizado em torno da dimensão do resultado do julgado, se favorável ou desfavorável seu desfecho.
Consideremos o seguinte caso de uso:
É possível imaginar que um advogado de um banco faça uma pesquisa de jurisprudência em determinado tribunal para avaliar a chance de êxito de uma nova demanda.
Tal como está indexada a base de julgados do STF, ele consegue, com alguma facilidade, encontrar casos concretos que trataram de um determinado tema. Contudo, o advogado tem muita dificuldade em encontrar, dentro desse tema, quais foram os casos vencidos por bancos e nos quais os mesmos bancos foram derrotados.
A utilidade de desenvolver uma solução que compreenda quais são os casos favoráveis e desfavoráveis está em viabilizar uma consulta agregada também por essa dimensão, referente ao resultado do julgado. Afinal, a consulta profissional tem quase sempre um lado interessado, de tal modo que saber qual o desfecho do caso é uma informação muito importante para a vida prática dos profissionais do Direito.
Nas próximas semanas, publicaremos por aqui a jornada de vários dos pesquisadores do DireitoTec, dedicados a mapear dezenas de milhares de julgados do STF. Isso permitirá criar uma base para treinamento de inteligência artificial, de tal modo que seja possível classificar automaticamente o desfecho de um acórdão. Que tal? Parece promissor?
Este post faz parte de uma série. Veja o post seguinte.
Os profissionais do Direito consomem diversos tipos de informação jurídica, sendo duas as principais: a lei e a jurisprudência. A lei é uma norma abstrata, ou seja, não foi aplicada a um caso concreto. Já a jurisprudência é uma norma concreta, feita para solucionar um caso submetido ao Poder Judiciário.
Embora seja relativamente fácil conhecer as leis, pois elas estão publicadas em repositórios oficiais, é muito mais complexo conhecer a jurisprudência. O repositório legislativo mais utilizado é o do Planalto e ele ilustra bem como são organizadas e consumidas as várias formas de legislação federal no Brasil. Em contraste, existem diversos tribunais e cada um é responsável por publicar sua própria jurisprudência.
De uma forma geral, os tribunais tratam esses dados como documentos em linguagem natural, com uma camada adicional relativamente limitada de metadados.
Assim, existem poucos filtros para acessar essa informação, por exemplo: a data do julgado, o nome do julgador, o órgão ao qual pertence esse julgador, o nome e a posição de cada parte no processo, etc. Não encontramos, contudo, nenhum repositório público organizado em torno da dimensão do resultado do julgado, se favorável ou desfavorável seu desfecho.
Consideremos o seguinte caso de uso:
É possível imaginar que um advogado de um banco faça uma pesquisa de jurisprudência em determinado tribunal para avaliar a chance de êxito de uma nova demanda.
Tal como está indexada a base de julgados do STF, ele consegue, com alguma facilidade, encontrar casos concretos que trataram de um determinado tema. Contudo, o advogado tem muita dificuldade em encontrar, dentro desse tema, quais foram os casos vencidos por bancos e nos quais os mesmos bancos foram derrotados.
A utilidade de desenvolver uma solução que compreenda quais são os casos favoráveis e desfavoráveis está em viabilizar uma consulta agregada também por essa dimensão, referente ao resultado do julgado. Afinal, a consulta profissional tem quase sempre um lado interessado, de tal modo que saber qual o desfecho do caso é uma informação muito importante para a vida prática dos profissionais do Direito.
Nas próximas semanas, publicaremos por aqui a jornada de vários dos pesquisadores do DireitoTec, dedicados a mapear dezenas de milhares de julgados do STF. Isso permitirá criar uma base para treinamento de inteligência artificial, de tal modo que seja possível classificar automaticamente o desfecho de um acórdão. Que tal? Parece promissor?
Este post faz parte de uma série. Veja o post seguinte.
O Presidente americano Donald Trump assinou recentemente (11/02/19) uma “executive order” para, nestas palavras, “manter a liderança” do país no campo da inteligência artificial. Embora seja inegável que os EUA desempenham um papel muito relevante nessa área, não é tão simples se colocar como líder. Aliás, a própria preocupação em manter uma suposta liderança demonstra que existe sim ao menos uma séria ameaça nessa corrida por IA, na qual a China vem se destacando bastante.
Mais que uma promessa: anos de orçamento
Para o desempenho dessa missão, foi designado um Comitê vinculado ao Conselho Nacional de Ciência e Tecnologia (NSTC), de tal modo que se espera uma coordenação ampla do governo federal americano, incluindo todas as suas agências. Diretores dessas agências são encorajados, desde já, a priorizar os investimentos em IA, fazendo com quem suas propostas de orçamento contemplem investimentos na área e, especialmente, durante os próximos anos.
Ou seja, existe uma preocupação em prover fundos para a iniciativa e o programa reconhece que o desenvolvimento de IA é algo que, além de dinheiro, consume também bastante tempo. E isso convive com um senso de urgência, pois o ato fixa um prazo de 90 dias para que cada agência indique como pretende empenhar seu orçamento anual para alcançar os objetivos fixados pela norma.
Princípios e objetivos estratégicos
O ato de Trump é guiado por cinco princípios: promoção da ciência, competitividade econômica e segurança nacional; redução das barreiras para experimentos com IA, de modo ampliar seu uso; educação dos cidadãos para encarar a revolução econômica provocada pela tecnologia; garantia das liberdades civis e da privacidade; bem como manutenção da posição estratégia dos EUA no mercado mundial de IA.
Parece um bom resumo de tudo que essa tecnologia promete em termos de avanços e também de riscos dela decorrentes. Assim, ao mesmo tempo que Trump reforça a importância estratégica de ser um protagonista na exportação de IA, delimita que esse ativo deve ser protegido para que não caia na mão de adversários comerciais e, principalmente, de inimigos. Trump também se mostra empenhado em manter a empregabilidade dos cidadãos americanos, tendo em vista a anunciada extinção [no meu modo de ver, de forma prematura] de diversas profissões.
Os princípios listados devem estar orientados a, no âmbito do governo federal, concretizar seis objetivos estratégicos: converter a pesquisa de IA em inovação aplicada à prática; aumentar a oferta de dados e ampliar o acesso a computadores especializados; preservar a segurança e a privacidade, mesmo diante da ampliação de usos de IA; diminuir a vulnerabilidade dos sistemas diante de ataques maliciosos; garantir que os empregados públicos e privados tenham condição de utilizar novas tecnologias; e, por fim, manter a liderança dos EUA na área.
O cronograma e os prazos
Além de fixar competências, princípios e objetivos estratégicos, a "executive order" cria um cronograma para que eles sejam alcançados. O primeiro passo é o aprimoramento no fornecimento de dados por parte do governo federal, que é reconhecido como um gargalo para o desenvolvimento de IA.
Está prevista uma chamada pública para, em 90 dias, identificar as demandas da sociedade civil e da academia em relação a quais serviços devem ser priorizados. Em 120 dias da publicação do ato, com o apoio do Ministério do Planejamento (OMB), o Comitê Federal de Inteligência Artificial (Select Committee) deve atualizar as orientações para a implementação de repositórios de dados e de software, com o objetivo de aprimorar o resgate e o uso da informação.
Além dessas previsões, a "executive order" cria uma séria de marcos urgentes para que o ciclo seja exitoso, tendo início pelas demandas dos cientistas de dados e fechamento pelo atendimento a elas. Ou seja, é um planejamento orientado pelo uso e pela finalidade que a sociedade deseja dar aos dados. O governo americano não está dizendo o que deve ser feito, chamando para si apenas o dever de organizar os dados, de sorte que não ocorram vazamentos ou violações à privacidade.
Minha opinião: corrida contra a China
No meu modo de ver, o novo ato de Trump é muito acertado e revela o real embate de duas potências. A China é a líder na coleta [inclusive de forma questionável] de informações e avança rapidamente com sua capacidade de processamento. Já os EUA podem ser até tidos como líderes na pesquisa de IA, mas dependem de mais dados para que se manter lutando. Por isso, o ato reorganiza as fundações da estrutura de dados públicos americanos. Afinal, sem dados é impossível fazer progresso em ciência de dados.
Pelo visto, quando o assunto é IA, a julgar pelos prazos e marcos delineados na norma americana, tempo também é dinheiro. Aliás, muito dinheiro. Prova disso é que os EUA estão refazendo as fundações, e não uma mera reforma no telhado.